LCS(Longest Common Subsequence, 최장 공통 부분 수열)문제는 두 수열이 주어졌을 때, 모두의 부분 수열이 되는 수열 중 가장 긴 것을 찾는 문제이다.
예를 들어, ACAYKP와 CAPCAK의 LCS는 ACAK가 된다.
입력
첫째 줄과 둘째 줄에 두 문자열이 주어진다. 문자열은 알파벳 대문자로만 이루어져 있으며, 최대 1000글자로 이루어져 있다.
출력
첫째 줄에 입력으로 주어진 두 문자열의 LCS의 길이를 출력한다.
예제
입력
출력
ACAYKP CAPCAK
4
문제풀이 코드
import sys
input = sys.stdin.readline
str1 = input().strip()
str2 = input().strip()
n, m = len(str1), len(str2)
dp = [[0] * (m+1) for _ in range(n+1)]
for i in range(1, n+1):
for j in range(1, m+1):
if str1[i-1] == str2[j-1]:
dp[i][j] = dp[i-1][j-1] + 1
else:
dp[i][j] = max(dp[i-1][j], dp[i][j-1])
print(dp[-1][-1])
풀이 방식: 동적 계획법(dp)를 이용하여 문제 풀이
1. str1과 str2배열을 순회하며 str1[i-1]과 str2[j-1]이 같을 때와 다를 때로 나눌 수 있다.
2. 만약 글자가 같다면 이전 문자가 추가되기 이전의 값에 +1을 해주면 된다 => dp[i][j] = dp[i-1][j-1] + 1
3. 글자가 다르다면 이전에 비교해왔던 값중 최대값으로 세팅해주면 된다. => dp[i][j] = max(dp[i-1][j], dp[i][j-1])
4. 이 두가지 점화식을 사용하여 반복문을 통해 두 문자열을 순회하며 dp배열을 초기화해주면 된다.
은기는 술병 N개(1부터 N까지 번호가 매겨져 있다)와 서랍 L개(1부터 L까지 번호가 매겨져 있다)를 가지고 있다. 술병은 은기의 방 바닥에 흩어져 있고, 어린이날을 맞이해 방 청소를 하려고 한다. 서랍에는 술병이 하나 들어갈 수 있다. 나중에 원하는 술을 빠르게 찾을 수 있게 하기 위해 은기는 각각의 술병이 들어갈 수 있는 서랍의 번호 Ai와 Bi를 공책에 적어 놓았다.
은기는 술병을 1번부터 N번까지 순서대로 정리할 것이고, 각각의 술병에 대해서 다음과 같은 과정을 거친다.
서랍 Ai가 비어있다면, i번 술을 그 서랍에 보관한다.
서랍 Bi가 비어있다면, i번 술을 그 서랍에 보관한다.
Ai에 들어있는 술을 다른 서랍으로 이동시킨다.(다른 서랍은 Ai에 들어있는 술이 들어갈 수 있는 서랍 중 하나이다) 만약, 그 서랍에도 이미 술이 들어있다면, 그 술을 다른 서랍으로 이동시킨다. 이런 과정을 거쳐서 빈 서랍을 하나 찾아 술을 모두 이동할 수 있는 경우에는, 술을 이동시키고 i번 술을 Ai에 보관한다. 불가능한 경우에는 다음 규칙으로 넘어간다.
Bi에 들어있는 술을 다른 서랍으로 이동시킨다. 만약, 그 서랍에도 이미 술이 들어있다면, 그 술을 다른 서랍으로 이동시킨다. 이런 과정을 거쳐서 빈 서랍을 하나 찾아 술을 모두 이동할 수 있는 경우에는, 술을 이동시키고 i번 술을 Bi에 보관한다. 불가능한 경우에는 다음 규칙으로 넘어간다.
위의 과정이 모두 불가능한 경우에는 i번 술을 그 자리에서 마셔버린다. (은기는 전혀 취하지 않는다)
각각의 술에 대해서, 서랍에 보관할 수 있는지, 그 자리에서 마셔버리는지를 구하는 프로그램을 작성하시오.
입력
첫째 줄에 N과 L이 주어진다. (1 ≤ N, L ≤ 300,000)
다음 N개 줄에는 Ai와 Bi가 주어진다. (1 ≤ Ai, Bi≤ L, Ai≠ Bi)
출력
1번 술부터 N번 술까지 순서대로 보관할 수 있는지, 그 자리에서 먹어야 하는지를 출력한다.
보관할 수 있는 경우에는 "LADICA"를, 먹어버려야 하는 경우에는 "SMECE"를 출력한다.
import sys
sys.setrecursionlimit(10000000)
input = sys.stdin.readline
N, L = map(int, input().split())
drawer = {x:x for x in range(1, L+1)}
have = {x:False for x in range(1, L+1)}
def find(x):
if x != drawer[x]:
drawer[x] = find(drawer[x])
return drawer[x]
def union(x, y):
rootX = find(x)
rootY = find(y)
drawer[rootX] = rootY
for i in range(N):
x, y = map(int, input().split())
if not have[x]:
have[x] = True
union(x, y)
print("LADICA")
elif not have[y]:
have[y] = True
union(y, x)
print("LADICA")
elif not have[find(x)]:
have[find(x)] = True
union(x, y)
print("LADICA")
elif not have[find(y)]:
have[find(y)] = True
union(y, x)
print("LADICA")
else:
print("SMECE")
풀이방식: 주어진 서랍과 서랍들의 부모서랍의 자리가 비어있는지 확인하는 문제이므로 union-find(응용)를 사용하여 문제 풀이
1. union과 find 함수를 생성
- find 함수는 기존 템플릿과 동일하지만, union은 기존과 조금 달라진다.
- union함수는 더 작은 값을 가지는게 아닌 y의 root값을 가져야 한다.
2. 문제를 4가지 경우로 분류할 수 있다.
첫번째. 서랍 A가 비어있을 때
두번째. 서랍 A의 부모서랍이 비어있을 때
세번째. 서랍 B가 비어있을 때
네번째. 서랍 B의 부모서랍이 비어있을 때
※ 부모서랍이 비었을 때를 확인하는 것은 현재 서랍이 비어있을 때 한칸씩 옮겨야 하기 때문이다.
3. union-find를 사용하기 위해 drawer와 서랍이 비어있는지 체크하기 위한 have를 생성한다.
4. 각 input을 받아오면서 2번에 해당하는 경우들을 체크한다.
5. 비어있는 서랍을 발견했다면 해당 서랍을 채워주고 union 함수를 호출하고 "LADICA"를 출력한다.
For example, given the equivalency information froms1 = "abc"ands2 = "cde","acd"and"aab"are equivalent strings ofbaseStr = "eed", and"aab"is the lexicographically smallest equivalent string ofbaseStr.
Returnthe lexicographically smallest equivalent string ofbaseStrby using the equivalency information froms1ands2.
Example 1:
Input
Output
s1 = "parker", s2 = "morris", baseStr = "parser"
"makkek"
Explanation: Based on the equivalency information in s1 and s2, we can group their characters as [m,p], [a,o], [k,r,s], [e,i]. The characters in each group are equivalent and sorted in lexicographical order. So the answer is "makkek".
Example 2:
Input
Output
s1 = "hello", s2 = "world", baseStr = "hold"
"hdld"
Explanation: Based on the equivalency information in s1 and s2, we can group their characters as [h,w], [d,e,o], [l,r]. So only the second letter 'o' in baseStr is changed to 'd', the answer is "hdld".
Explanation: We group the equivalent characters in s1 and s2 as [a,o,e,r,s,c], [l,p], [g,t] and [d,m], thus all letters in baseStr except 'u' and 'd' are transformed to 'a', the answer is "aauaaaaada".
Constraints:
1 <= s1.length, s2.length, baseStr <= 1000
s1.length == s2.length
s1,s2, andbaseStrconsist of lowercase English letters.
문제풀이 코드
class Solution:
def smallestEquivalentString(self, s1: str, s2: str, baseStr: str) -> str:
UF = {}
def find(x):
if x not in UF:
UF[x] = x
if x != UF[x]:
print(x, UF[x])
UF[x] = find(UF[x])
return UF[x]
def union(x, y):
# 두 값의 루트값을 탐색
rootX = find(x)
rootY = find(y)
# 두 루트값 중 더 작은 값을 루트노드로 초기화한다
if rootX > rootY:
UF[rootX] = rootY
else:
UF[rootY] = rootX
for i in range(len(s1)):
union(s1[i], s2[i])
answer = ""
for s in baseStr:
answer += find(s)
return answer
풀이방식: 서로 연결된 알파벳들은 연결된 알파벳 중 가장 작은 알파벳으로 루트값을 가져가야 하기 때문에 Union-Find 알고리즘 사용
You are given atree(i.e. a connected, undirected graph that has no cycles)rootedat node0consisting ofnnodes numbered from0ton - 1. The tree is represented by a0-indexedarrayparentof sizen, whereparent[i]is the parent of nodei. Since node0is the root,parent[0] == -1.
You are also given a stringsof lengthn, wheres[i]is the character assigned to nodei.
Returnthe length of thelongest pathin the tree such that no pair ofadjacentnodes on the path have the same character assigned to them.
Example 1:
Input: parent = [-1,0,0,1,1,2], s = "abacbe"
Output: 3
Explanation: The longest path where each two adjacent nodes have different characters in the tree is the path: 0 -> 1 -> 3. The length of this path is 3, so 3 is returned.
It can be proven that there is no longer path that satisfies the conditions.
Input
Output
parent = [-1,0,0,1,1,2], s = "abacbe"
3
Explanation: The longest path where each two adjacent nodes have different characters in the tree is the path: 0 -> 1 -> 3. The length of this path is 3, so 3 is returned. It can be proven that there is no longer path that satisfies the conditions.
Example 2:
Input: parent = [-1,0,0,0], s = "aabc"
Output: 3
Explanation: The longest path where each two adjacent nodes have different characters is the path: 2 -> 0 -> 3. The length of this path is 3, so 3 is returned.
>Input
Output
parent = [-1,0,0,0], s = "aabc"
3
Explanation: The longest path where each two adjacent nodes have different characters is the path: 2 -> 0 -> 3. The length of this path is 3, so 3 is returned.
Constraints:
n == parent.length == s.length
1 <= n <= 105
0 <= parent[i] <= n - 1for alli >= 1
parent[0] == -1
parentrepresents a valid tree.
sconsists of only lowercase English letters.
문제풀이 코드
class Solution:
def longestPath(self, parent: List[int], s: str) -> int:
n = len(parent)
tree = defaultdict(list)
for end, start in enumerate(parent):
tree[start].append(end)
answer = 1
def dfs(node):
nonlocal answer
res = 1
for child in tree[node]:
l = dfs(child)
if s[node] != s[child]:
answer = max(answer, res + l)
res = max(res, l+1)
return res
dfs(0)
return answer
1. 트리형태의 그래프를 만들어 준다. ex) {0:[1,2], 1:[3,4], 2:[5]}
2. 최소값은 자기 노드 하나이기 때문에 answer를 1로 초기화
3. 그래프를 탐색하기 위한 dfs 함수를 만들어준다.
- 현재 연결된 노드의 최솟값은 1이기 때문에 현재 연결된 노드들을 1로 선언
- 현재 노드의 자식노드들을 탐색한다.
- 노드를 탐색할 때 l = dfs(child)를 통해 자식노드가 그 하위노드와 연결된 최대값을 가져온다.
- 현재 알파벳과 자식노드의 알파벳이 다를 때 answer와 res를 초기화해준다.
-> answer = max(answer, res+l): res+l 은 현재의 노드부터 이전에 연결된 노드들의 갯수로 초기화해준다.
-> res = max(res, l+1): l+1은 이전 연결된 노드에 현재 노드를 연결한 값으로 초기화해준다.
4. dfs가 종료되면 answer에는 최대로 연결된 노드의 개수가 들어가있기 때문에 answer를 반환한다.
Given anm x ngrid of charactersboardand a stringword, returntrueifwordexists in the grid.
The word can be constructed from letters of sequentially adjacent cells, where adjacent cells are horizontally or vertically neighboring. The same letter cell may not be used more than once.
Example 1:
Input
Output
board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]] word = "ABCCED"
true
Example 2:
Input
Output
board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]] word = "SEE"
true
문제풀이 코드
class Solution:
def exist(self, board: List[List[str]], word: str) -> bool:
row, col = len(board), len(board[0])
visited = [[False] * col for _ in range(row)]
def dfs(x,y,s):
if s == len(word):
return True
if x < 0 or x > row-1 or y < 0 or y > col-1 or word[s] != board[x][y] or visited[x][y]:
return False
visited[x][y] = True
res = (dfs(x+1,y, s+1) or dfs(x,y+1, s+1) or
dfs(x-1,y, s+1) or dfs(x,y-1, s+1))
visited[x][y] = False
return res
for i in range(row):
for j in range(col):
if dfs(i,j,0):
return True
return False
주어진 알파벳들로 주어진 단어를 만들 수 있는지 체크하는 것이기 때문에 dfs를 이용하여 문제풀이
1. 좌,우,위.아래를 탐색해야 되기 때문에 현재 x,y가 조건에 맞는지 체크한다.
2. 그리고 가장 핵심이 되는 현재 연결된 단어가 word의 부분인지 확인하기 위해 현재 알파벳과, word의 s번째 순서의 알파벳이 같은지 비교한다.
3. 조건을 만족했을 때, 모든 방향으로 dfs를 호출한다. 4. 호출된 dfs중 하나라도 True가 존재하면 res는 True가 된다.
어떤 도시의 지하철 노선에 대한 정보가 주어졌을 때, 출발지에서 목적지까지의 최소 환승 경로를 구하는 프로그램을 작성하시오. 실제 경로를 구할 필요는 없고, 환승 회수만을 구하면 된다.
입력
첫째 줄에 역의 개수 N(1≤N≤100,000), 노선의 개수 L(1≤L≤100,000)이 주어진다. 다음 L개의 줄에는 각 노선이 지나는 역이 순서대로 주어지며 각 줄의 마지막에는 -1이 주어진다. 마지막 줄에는 출발지 역의 번호와 목적지 역의 번호가 주어진다. 역 번호는 1부터 N까지의 정수로 표현된다. 각 노선의 길이의 합은 1,000,000을 넘지 않는다.
출력
첫째 줄에 최소 환승 회수를 출력한다. 불가능한 경우에는 -1을 출력한다.
예제
입력
출력
10 3 1 2 3 4 5 -1 9 7 10 -1 7 6 3 8 -1 1 10
2
문제풀이 코드
from collections import defaultdict, deque
import sys
input = sys.stdin.readline
def bfs(start, end, subways):
if start == end:
return 0
visited_subway = [False for _ in range(len(subways))]
visited_station = [False for _ in range(N + 1)]
dq = deque()
for subway in graph[start]:
dq.append((subway, 0))
visited_subway[subway] = True
visited_station[start] = True
while dq:
subway, count = dq.popleft()
# 현재 지하철이 갈 수 있는 지하철역을 탐색
for station in subways[subway]:
# 방문했던 지하철역이면 패스
if visited_station[station]:
continue
# 현재 역이 도착역과 같으면 return
if station == end:
return count
visited_station[station] = True
for trans in graph[station]:
# 한번도 타지않은 지하철일 때 dq에 삽입
if not visited_subway[trans]:
dq.append((trans, count+1))
visited_subway[trans] = True
return -1
N, L = map(int, input().split())
# 지하철역에서 탈수있는 호선
graph = defaultdict(list)
# 호선이 지나는 지하철역
subways = []
for i in range(L):
lst = list(map(int, input().split()))
subways.append(lst[:-1])
for l in lst:
if l == -1:
continue
graph[l].append(i)
start, end = map(int, input().split())
result = bfs(start, end, subways)
print(result)
문제를 접하고 그래프 탐색 알고리즘인건 알았지만 그래프를 어떻게 세팅해야할지 삽질을 많이했고, 문제를 해결하면서 시간초과가 나서 이를 해결하기위해 또 많은 시간을 썻다....
1. 지하철 호선이 갈 수 있는 지하철역을 담은 배열과, 지하철역에서 탈 수 있는 호선을 담은 딕셔너리(배열도 상관없음)를 만들어준다.
2. 시작역과 도착역의 최소 환승을 구하는 문제이기 때문에 bfs를 만들어 준다.
3. bfs는 일반적인 것과 크게 다르지 않다.
- 환승의 횟수를 구하기 위해 환승 횟수를 count하는 변수를 dq에 추가로 담아준다.
- 지하철역과, 호선을 중복탐색하지 않도록 visited 리스트를 각각 생성해준다.
- 현재 호선이 갈 수 있는 모든 지하철역을 탐색한다.(이전에 탐색한적이 없는 지하철역만)
- 지하철역에서 탈 수 있는 모든 호선을 dq에 넣어준다.(이전에 탐색한적이 없는 호선만)
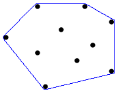
다각형의 임의의 두 꼭짓점을 연결하는 선분이 항상 다각형 내부에 존재하는 다각형을 볼록 다각형이라고 한다. 아래 그림에서 (a)는 볼록 다각형이며, (b)는 볼록 다각형이 아니다.
조금만 생각해 보면 다각형의 모든 내각이 180도 이하일 때 볼록 다각형이 된다는 것을 알 수 있다. 편의상 이 문제에서는 180도 미만인 경우만을 볼록 다각형으로 한정하도록 한다.
2차원 평면에 N개의 점이 주어졌을 때, 이들 중 몇 개의 점을 골라 볼록 다각형을 만드는데, 나머지 모든 점을 내부에 포함하도록 할 수 있다. 이를 볼록 껍질 (CONVEX HULL) 이라 한다. 아래 그림은 N=10인 경우의 한 예이다.
점의 집합이 주어졌을 때, 볼록 껍질을 이루는 점의 개수를 구하는 프로그램을 작성하시오.
입력
첫째 줄에 점의 개수 N(3 ≤ N ≤ 100,000)이 주어진다. 둘째 줄부터 N개의 줄에 걸쳐 각 점의 x좌표와 y좌표가 빈 칸을 사이에 두고 주어진다. 주어지는 모든 점의 좌표는 다르다. x좌표와 y좌표의 범위는 절댓값 40,000을 넘지 않는다. 입력으로 주어지는 다각형의 모든 점이 일직선을 이루는 경우는 없다.
출력
첫째 줄에 볼록 껍질을 이루는 점의 개수를 출력한다.
볼록 껍질의 변에 점이 여러 개 있는 경우에는 가장 양 끝 점만 개수에 포함한다.
예제
입력
출력
8 1 1 1 2 1 3 2 1 2 2 2 3 3 1 3 2
5
문제풀이 코드
import sys
input = sys.stdin.readline
def ccw(A, B, C):
return (B[0] - A[0]) * (C[1] - A[1]) - (B[1] - A[1]) * (C[0] - A[0])
n = int(input())
points = []
for _ in range(n):
x, y = map(int, input().split())
points.append([x, y])
# 시계 반대방향으로 정렬 시작
points.sort()
start = points[0]
points.remove(start)
inf = []
for i in range (n-1):
if start[0] == points[i][0]:
# 시작점와 같은 y축에 있는 좌표는 따로 빼준다
inf.append(points[i])
else:
# 두 점사이에 기울기를 추가
points[i].append((start[1]-points[i][1])/(start[0]-points[i][0]))
for i in inf:
points.remove(i)
# 기울기를 기준으로 정렬
points.sort(key=lambda x : x[2])
for i in inf:
points.append(i)
# 정렬 종료
stack = []
stack.append(start)
stack.append(points[0])
# Convex Hull(Graham's Scan)
for i in range(1, len(points)):
# 평행을 이루고 있거나, 시계방향으로 갈 때는 스택에서 제거한다.
while len(stack) >= 2 and ccw(stack[-2], stack[-1], points[i]) <= 0:
stack.pop()
stack.append(points[i])
print(len(stack))
이전엔 Monotone Chain 알고리즘을 사용하여 Convex Hull 문제를 해결했고, 이번 문제는 Graham's Scan 알고리즘을 사용하여 문제를 해결했다. ccw를 이용한 스캔과정을 이전과 유사하나, 위 아래로 탐색하는것이 아니기 때문에 중복되는 좌표를 제거하지 않아도 된다.
1. 그레이엄 스캔을 시작하기 이전에 모든 점은 시계 반대방향으로 정렬되어 있어야 한다.
2. 시작지점을 가져오기 위해서 x축을 기준으로 점들을 정렬한다.
3. 첫번째에 있는 점을 시작포인트로 가져오고, 배열에서 제거한다.
4. 시계 반대방향으로 정렬하기 위해서, 시작점과 points[i]의 기울기를 구하여 추가해준다.(시작점과 y좌표가 같은 점들은 따로 빼둠)
5. 추가된 기울기를 기준으로 배열을 정렬하면 시계 반대방향으로 정렬하게 되고, 이전에 제거했던 시작점과 y좌표가 같은 점을 추가
6. 해당 문제는 한 직선에 점은 두개만 있으면 되기 때문에 ccw에서 받은 값이 0보다 작거나 같을 때 스택에서 pop해준다.
7. 반복문이 종료되면 스택에는 볼록껍질에 해당하는 점만 들어가있기 때문에 스택의 길이를 반환한다.
때때로 주어진 점들 사이에서 볼록 껍질(Convex Hull)을 찾아내는 기술은 요긴하게 쓰인다. ACM 월드파이널에서 볼록 껍질을 응용해야 하는 문제가 출제되다 보니, 이걸 할 줄 아는 것은 참가자의 소양이 되었다.
이 작업은 크게 두 단계의 과정으로 이루어진다. 첫 번째 단계는 볼록 껍질을 이루는 점들을 찾아내는 것이고, 두 번째 단계는 이 점들을 반시계 방향으로 순서를 매기는 것이다. 첫 번째 단계는 이미 완료되었다고 할 때, 두 번째 단계를 수행하는 프로그램을 작성하시오.
입력
첫 번째 줄에는 점의 개수 n이 주어진다. (3 <= n <= 100,000)
두 번째 줄부터 n개의 줄에 걸쳐 각 점에 대한 정보 x, y, c가 주어진다. x, y는 정수이며 절댓값이 1,000,000,000을 넘지 않고, c는 Y 또는 N인 문자이다. Y는 이 점이 볼록 껍질에 속해있음을, N이면 아님을 의미한다.
중복되는 점은 없으며, 모든 점이 한 직선 위에 있는 경우도 없다.
출력
첫 번째 줄에 볼록 껍질을 이루는 점의 개수를 출력한다.
이어서 한 줄에 하나씩 그 점들의 좌표를 x y 형태로 출력하는데, 이 점들은 반시계 방향으로 순서를 이루어야 한다. 첫 번째 좌표는 x좌표가 가장 작은 점이어야 하며, 만약 그런 좌표가 여러 개라면 그 중에서 y좌표가 가장 작은 점을 선택한다.
예제
입력
출력
5 1 1 Y 1 -1 Y 0 0 N -1 -1 Y -1 1 Y
4 -1 -1 1 -1 1 1 -1 1
문제풀이 코드
import sys
from itertools import chain
input = sys.stdin.readline
N = int(input())
# 세 점의 방향 관계를 구함(반시계방향)
def ccw(A, B, C):
return (B[0] - A[0]) * (C[1] - A[1]) - (B[1] - A[1]) * (C[0] - A[0])
points = []
for _ in range(N):
x, y, c = map(str, input().split())
points.append([int(x),int(y)])
points.sort()
stack = []
# Monotone Chain
for i in chain(range(len(points)), reversed(range(len(points) - 1))):
while len(stack) >= 2 and ccw(stack[-2], stack[-1], points[i]) < 0:
stack.pop()
stack.append(points[i])
# 중복 껍질 제거
stack.pop()
for i in range(1, (len(stack) + 1) // 2):
if stack[i] != stack[-1]:
break
stack.pop()
print(len(stack))
for s in stack:
print(s[0], s[1])
해당 문제는 볼록껍질에 속해있는 좌표를 알 수 있지만 모든 좌표가 주어졌기 때문에 전체 좌표에서 볼록껍질에 해당하는 부분을 구하여 반환하는 방법으로 문제를 해결했고, ConvexHull 알고리즘 중에 Monotone Chain을 이용하였다. 이유는 Graham's Scan은 좌표를 반시계방향으로 정렬해야하는 과정을 거쳐야하기 때문에 좀 더 간단한 Monotone Chain을 사용하기로 했다.
1. Monotone Chain은 껍질의 윗방향과 아랫방향을 만들어 합치기 때문에 chain을 이용하여 반복문을 (0 ~ n ~ 0)으로 돌도록 만든다.
2. stack에는 ccw로 체크를 하기위해 최소 2개의 좌표가 들어가있어야 한다.
3. ccw의 결과가 시계방향이면 0보다 작은값, 평행하면 0, 시계 반대방향이면 0보다 큰 값을 반환한다.
4. stack[-2], stack[-1], points[i]를 A, B, C로 두고 해당 좌표들이 시계 반대방향으로 돌고있으면 현재 좌표를 스택에 넣어주고
5. 세 좌표가 조건을 만족하지 못하면 stack에 있는 값을 하나씩 뽑아준다.
6. 좌표를 구하는 과정이 종료되면 Monotone Chain 알고리즘은 위아래를 합치는 것이기 때문에 중복된 껍질을 제거한다.